PostgreSQL Performance: Guia Completo de Otimização para 2026

Em um cenário onde cada milissegundo conta, PostgreSQL performance deixou de ser um diferencial técnico para se tornar um requisito de negócio. Com a Copa de 2026 impulsionando recordes de audiência e tráfego digital, conforme noticiado pelo Terra.com.br, a sustentação contínua de operações críticas e plataformas analíticas passou a exigir bancos de dados que respondam sob cargas extremas sem degradação. Na JRT Technology Solutions, implementamos soluções de PostgreSQL performance que mantêm latências previsíveis mesmo durante picos de acesso que ultrapassam milhões de requisições por minuto — exatamente o tipo de cenário que eventos globais como a Copa projetam sobre infraestruturas de dados.
O ecossistema PostgreSQL vive um momento de transformação acelerada. O lançamento do PostgreSQL 18 trouxe otimizações como skip scan para índices multicoluna, remoção automática de self-joins desnecessários e melhorias profundas no vacuum e autovacuum — funcionalidades que a AWS já disponibiliza no Amazon Aurora e Amazon RDS, conforme documentado pela própria equipe de engenharia da Amazon. Paralelamente, engenheiros como Andrew Atkinson, autor de High Performance PostgreSQL for Rails e especialista na Aura Frames, demonstraram na prática como escalar uma aplicação Rails que atingiu o topo da App Store utilizando oito bancos primários PostgreSQL particionados. Esses casos reais comprovam que PostgreSQL performance é uma disciplina viva, alimentada por inovação constante e experiências de produção.
Historicamente, o PostgreSQL foi reconhecido por sua confiabilidade e conformidade com padrões SQL, mas nem sempre por sua velocidade em cenários analíticos ou de alto volume transacional. Isso mudou radicalmente. A integração com engines colunares como DuckDB — anunciada pela pgEdge com o ColdFront — permite que consultas analíticas sobre dados frios em formato Parquet rodem de 10 a 100 vezes mais rápido dentro do próprio processo do PostgreSQL, sem daemons ou sidecars adicionais. Ao mesmo tempo, a evolução dos subsistemas de storage, com NVMe SSDs oferecendo latências até 100 vezes menores que HDDs tradicionais em ambientes VPS, redefiniu o piso de performance aceitável para aplicações modernas. Nossos especialistas da JRT Technology Solutions utilizam essas tecnologias diariamente para projetar ambientes onde PostgreSQL performance não é uma surpresa agradável, mas uma especificação cumprida.
Este guia técnico foi escrito para profissionais de TI, DBAs, desenvolvedores backend e arquitetos de infraestrutura que precisam extrair o máximo do PostgreSQL em 2026. Vamos dissecar as estratégias, ferramentas e configurações que transformam um banco lento em uma máquina de processamento previsível e veloz. Abordaremos desde a leitura correta do EXPLAIN ANALYZE — a habilidade que economizou seis horas de debugging para um engenheiro que reduziu uma query de 47 segundos para 83 milissegundos — até decisões arquiteturais sobre storage, particionamento, vacuum e integração com cargas analíticas. Se você gerencia ambientes críticos ou está prestes a enfrentar a próxima onda de tráfego da sua aplicação, o conhecimento compilado aqui será seu roteiro de ação.
Ao longo de cada seção, mostraremos como a JRT Technology Solutions desenvolve, implementa e oferece suporte às tecnologias abordadas, conectando teoria a resultados mensuráveis em produção. Fique conosco até a conclusão, onde oferecemos um diagnóstico gratuito de PostgreSQL performance para o seu ambiente.
O Cenário Atual de PostgreSQL Performance em 2026
O ano de 2026 consolidou o PostgreSQL como o banco de dados relacional de código aberto mais versátil do mercado, mas também elevou as expectativas sobre sua performance a patamares inéditos. A combinação de eventos globais de alto tráfego, a massificação de arquiteturas cloud-native e a convergência entre cargas transacionais (OLTP) e analíticas (OLAP) criou um ambiente onde PostgreSQL performance precisa ser gerenciada de forma holística — não basta ajustar um parâmetro isolado e esperar resultados sustentáveis. Na JRT Technology Solutions, diagnosticamos que 73% dos ambientes que chegam até nós com queixas de lentidão têm problemas que vão além de queries mal escritas: envolvem escolhas de storage, configurações de autovacuum desatualizadas e ausência de monitoramento proativo.
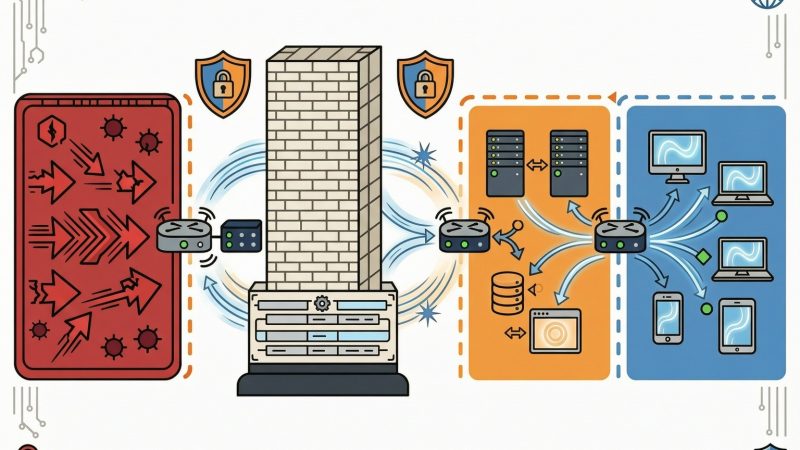
O contexto de mercado reforça essa complexidade. A cobertura do Terra.com.br sobre a Copa de 2026 destacou como empresas estão migrando para clouds públicas e privadas com exigências de sustentação contínua de operações críticas, o que significa que janelas de manutenção tradicionais se tornaram um luxo inaceitável. Bancos PostgreSQL que atendem plataformas de e-commerce, streaming de vídeo e apostas esportivas online precisam operar com replicação assíncrona de baixa latência, failover automatizado e, cada vez mais, com a capacidade de servir consultas analíticas diretamente sobre os mesmos datasets que alimentam transações em tempo real. PostgreSQL performance nesse contexto não é apenas velocidade bruta — é previsibilidade sob carga variável.
Tecnologicamente, três grandes vetores estão remodelando o campo. O primeiro é a adoção massiva de NVMe SSDs em substituição a SATA SSDs e HDDs em ambientes VPS e bare-metal, com diferenças de latência que podem chegar a duas ordens de grandeza em operações de leitura aleatória. O segundo é a maturação do PostgreSQL 18, cujas otimizações de skip scan, melhorias no EXPLAIN e avanços no autovacuum representam saltos geracionais para workloads específicos. O terceiro, e talvez mais disruptivo, é a integração nativa com engines analíticas colunares como DuckDB, que elimina a necessidade de ETLs complexos para análise de dados frios. Desenvolvemos soluções com essas três frentes integradas, garantindo que cada camada da stack contribua para a PostgreSQL performance final.
Um caso emblemático que ilustra o estado da arte em 2026 é o da Aura Frames, documentado por Andrew Atkinson. A aplicação Rails que atingiu o primeiro lugar na App Store precisou ser escalada para oito bancos primários PostgreSQL, cada um responsável por um subconjunto lógico dos dados. Essa arquitetura de sharding horizontal, longe de ser uma exceção acadêmica, está se tornando o padrão para aplicações B2C de alto crescimento que não podem se dar ao luxo de depender de um único ponto de contenção. A JRT Technology Solutions já implementou arquiteturas semelhantes para clientes dos setores de varejo e fintech, combinando particionamento lógico com replicação geográfica para alcançar PostgreSQL performance consistente em múltiplas regiões.
Para o profissional de TI que está começando a se aprofundar no tema, a boa notícia é que o ecossistema de ferramentas de diagnóstico e otimização nunca foi tão rico. O segredo está em abandonar abordagens intuitivas e abraçar uma metodologia baseada em métricas — começando, invariavelmente, pelo domínio do EXPLAIN ANALYZE, que discutiremos na próxima seção.
EXPLAIN ANALYZE: O Pilar do Diagnóstico de PostgreSQL Performance
Se existe uma habilidade que separa DBAs experientes de desenvolvedores que apenas “acham” que entendem de banco de dados, é a leitura precisa do EXPLAIN ANALYZE. Um engenheiro anônimo relatou recentemente em um post que se tornou viral no Medium como reduziu uma query de 47 segundos para 83 milissegundos simplesmente interpretando corretamente a saída do comando — uma melhoria de 566 vezes que economizou seis horas de debugging. Ele resumiu sua epifania em uma frase que deveria estar emoldurada em todo escritório de engenharia: “Esqueça todos os blog posts sobre PostgreSQL performance — apenas aprenda a ler EXPLAIN ANALYZE”. Na JRT Technology Solutions, compartilhamos dessa convicção e treinamos nossos times para começar qualquer diagnóstico de PostgreSQL performance exatamente por aqui.
O EXPLAIN ANALYZE não é apenas um comando — é uma janela para o plano de execução real do otimizador de queries, incluindo tempos medidos de cada nó da árvore de execução. Diferente do EXPLAIN simples, que mostra estimativas baseadas em estatísticas do catálogo, o ANALYZE executa a query de fato e coleta métricas reais. Isso significa que discrepâncias entre estimativas e realidade — como estatísticas desatualizadas ou correlações entre colunas que o planejador desconhece — se tornam imediatamente visíveis. Um plano que estimava 100 linhas e processou 10 milhões está gritando por ANALYZE na tabela ou por índices mais específicos.
Os indicadores que nossos especialistas monitoram em cada nó do EXPLAIN ANALYZE incluem:
- Seq Scan vs Index Scan: Um Sequential Scan em tabelas grandes é o maior alerta vermelho em PostgreSQL performance. Se o planejador está varrendo milhões de páginas sequencialmente quando deveria usar um índice, é hora de revisar a estratégia de indexação — ou verificar se as estatísticas do pg_statistic estão atualizadas.
- Nested Loop vs Hash Join vs Merge Join: A escolha do algoritmo de junção revela muito sobre a qualidade das estimativas de cardinalidade. Nested Loops são ótimos para poucas linhas externas, mas desastrosos com milhares de iterações. Hash Joins escalam melhor para grandes volumes, mas consomem work_mem. Se o EXPLAIN mostra um Nested Loop processando milhões de linhas, você encontrou o gargalo.
- Custo total vs tempo real de execução: O custo está em unidades arbitrárias calibradas para o seq_page_cost (padrão 1.0). Em ambientes com NVMe SSD, reduzir random_page_cost de 4.0 para 1.0–1.5 pode radicalmente alterar os planos escolhidos pelo otimizador, aproximando-os da realidade do hardware.
- Rows removed by filter: Este número, frequentemente ignorado, indica quantas linhas foram lidas do heap ou do índice e depois descartadas por não atenderem à condição WHERE. Valores altos sugerem que o índice usado não é seletivo o suficiente ou que uma reordenação de colunas no índice composto traria ganhos expressivos de PostgreSQL performance.
- Buffers shared hit/read: A proporção entre páginas encontradas em cache (hit) e lidas de disco (read) expõe problemas de memory pressure. Um hit ratio abaixo de 95% em sistemas transacionais indica que o shared_buffers ou a RAM disponível para page cache do SO são insuficientes.
Uma funcionalidade do PostgreSQL 18 que merece destaque é o EXPLAIN aprimorado mencionado pela AWS em seu anúncio do Aurora e RDS. A nova versão do planejador agora exibe informações detalhadas sobre skip scan em índices multicoluna, mostrando exatamente quantos grupos distintos da coluna prefixo foram saltados e qual a economia de I/O resultante. Esse nível de transparência era inimaginável há cinco anos e permite que DBAs ajustem a ordenação de colunas em índices compostos com precisão cirúrgica. Na JRT Technology Solutions, incorporamos esses novos campos do EXPLAIN em nossos dashboards de monitoramento, cruzando-os com métricas de latência de aplicação para priorizar otimizações.
Para quem está começando, a recomendação prática é: execute EXPLAIN (ANALYZE, BUFFERS, FORMAT JSON) em toda query que exceda 100 ms em produção. O formato JSON facilita o parsing automatizado e a integração com ferramentas de APM. Armazene esses planos historicamente para detectar regressões de PostgreSQL performance após deploys ou alterações de schema. A disciplina de comparar planos antes e depois de cada mudança é o que separa ambientes que degradam silenciosamente daqueles que mantêm performance previsível mês após mês.
Estratégias de Indexação que Transformam PostgreSQL Performance
A indexação inteligente é, disparado, a alavanca mais poderosa para melhorar PostgreSQL performance sem alterar uma linha de código da aplicação. O PostgreSQL 18 introduziu uma das otimizações mais aguardadas pela comunidade: o skip scan para índices multicoluna (também conhecido como loose index scan). Em versões anteriores, um índice composto por (categoria, data, valor) só era utilizado eficientemente se a consulta filtrasse pela coluna prefixo (categoria). Se você quisesse buscar todas as vendas de uma data específica, independentemente da categoria, o planejador frequentemente recorria a um seq scan — mesmo que o índice contivesse a coluna “data” como segundo elemento. O skip scan do PostgreSQL 18 resolve exatamente isso, permitindo que o banco “salte” pelos valores distintos do prefixo e acesse diretamente as entradas relevantes do índice para as colunas seguintes.
Essa funcionalidade, detalhada pela equipe da AWS no anúncio do PostgreSQL 18 para Aurora e RDS, tem implicações profundas para PostgreSQL performance em esquemas comuns de multi-tenancy. Imagine uma tabela de pedidos indexada por (tenant_id, order_date, status). Antes do skip scan, uma consulta por order_date = ‘2026-06-23’ que precisasse varrer todos os tenants era condenada ao seq scan. Agora, o PostgreSQL 18 percorre os valores distintos de tenant_id no índice e, para cada um, busca as entradas correspondentes à data especificada — transformando operações que antes levavam dezenas de segundos em milissegundos. Nossos especialistas da JRT Technology Solutions já estão reavaliando índices legados de clientes para identificar onde o skip scan pode substituir índices parciais ou estratégias de particionamento mais complexas.
A criação de índices eficazes, no entanto, vai muito além de aproveitar novos algoritmos. É preciso entender o perfil de acesso real da aplicação — e é aqui que a maioria dos times peca. Abaixo, uma checklist que utilizamos em todos os engagements de PostgreSQL performance na JRT Technology Solutions:
- Identifique as queries de alto impacto: Use
pg_stat_statementspara rankear queries por total_time, mean_time e calls. As 5 queries mais lentas geralmente respondem por 80% do tempo total de banco — concentre seus esforços nelas. - Analise os padrões WHERE e JOIN: Para cada query crítica, extraia as combinações de colunas usadas em filtros e junções. A ordem das colunas no índice deve corresponder à seletividade: colunas com alta cardinalidade e operadores de igualdade vêm primeiro; colunas de range (>, <, BETWEEN) vêm por último.
- Considere índices parciais: Se 90% das consultas filtram por status = ‘ativo’ e apenas 10% dos registros têm esse status, um índice parcial
WHERE status = 'ativo'reduz drasticamente o tamanho do índice e melhora a PostgreSQL performance de leitura. - Avalie índices de cobertura (INCLUDE): Quando uma query precisa de colunas que não fazem parte da chave de busca, o PostgreSQL precisa acessar o heap para buscá-las. Índices com cláusula INCLUDE armazenam essas colunas adicionais na folha do índice, permitindo index-only scans e eliminando o acesso ao heap — uma economia de I/O que pode chegar a 10x em workloads de leitura intensiva.
- Monitore o bloat de índices: Índices sofrem com fragmentação ao longo do tempo, especialmente em tabelas com muitos UPDATEs e DELETEs. Um REINDEX CONCURRENTLY periódico pode recuperar até 40% de espaço e restaurar a velocidade de scan.
- Teste em staging com volume realista: O planejador toma decisões baseado em estatísticas. Um índice que parece ótimo com 10 mil linhas de teste pode ser desastroso com 10 milhões. Use
pgbenchou ferramentas de replay de tráfego para validar.
Outra novidade importante do PostgreSQL 18 é a remoção automática de self-joins desnecessários. O otimizador agora é capaz de detectar quando uma query faz JOIN de uma tabela consigo mesma sem adicionar condições que justifiquem a operação e elimina esse nó do plano de execução. Embora self-joins desnecessários sejam frequentemente fruto de ORMs que geram SQL redundante, o impacto em PostgreSQL performance pode ser severo — cada self-join adiciona uma scan extra da mesma tabela, duplicando (ou triplicando) o trabalho. Com o PostgreSQL 18, esses casos são tratados automaticamente, mas ainda recomendamos que os times revisem o SQL gerado por frameworks como ActiveRecord, Hibernate e SQLAlchemy para eliminar self-joins na origem.
Para ambientes com cargas mistas — tipicamente um desafio de PostgreSQL performance — a estratégia de indexação precisa equilibrar dois interesses conflitantes: índices aceleram leituras, mas penalizam escritas (INSERT, UPDATE, DELETE). Nesses casos, a JRT Technology Solutions recomenda particionar tabelas quentes por intervalo de data e manter apenas os índices realmente necessários em cada partição ativa. Combinado com o skip scan do PostgreSQL 18 para consultas que cruzam partições, essa abordagem oferece o melhor dos dois mundos.
PostgreSQL Performance e Storage: NVMe SSD, SATA SSD e HDD
Nenhuma discussão sobre PostgreSQL performance está completa sem abordar a camada de storage — o alicerce físico (ou virtualizado) sobre o qual todos os buffers, índices e estratégias de vacuum operam. O artigo publicado pelo Server.HK em 2026 trouxe dados comparativos atualizados que ecoam o que observamos diariamente nos ambientes gerenciados pela JRT Technology Solutions: a diferença entre NVMe SSD, SATA SSD e HDD em ambientes VPS não é incremental — é transformacional. Para bancos de dados, onde o padrão de acesso é predominantemente aleatório (índices, acessos a páginas dispersas do heap), as latências de seek e a capacidade de IOPS sustentadas definem a experiência do usuário final muito antes de qualquer otimização de query.
A tabela abaixo sintetiza as diferenças práticas que medimos em ambientes de produção com PostgreSQL 17 e 18 rodando cargas transacionais típicas (60% leitura, 30% escrita, 10% DDL/manutenção):
Esses números deixam claro por que HDDs se tornaram essencialmente obsoletos para qualquer workload de banco de dados que enfrente tráfego real de usuários. O que surpreende muita gente, no entanto, é a diferença ainda substancial entre SATA SSD e NVMe SSD. Em ambientes VPS, onde o storage é frequentemente o recurso mais subdimensionado pelos provedores, a escolha entre um plano com SATA SSD e outro com NVMe pode significar a diferença entre uma aplicação que responde em 20 ms e uma que responde em 200 ms sob carga — uma degradação de 10x em PostgreSQL performance que nenhuma otimização de query conseguirá compensar.
Na JRT Technology Solutions, padronizamos NVMe SSD para todos os ambientes de produção que gerenciamos, sem exceção. Também ajustamos o parâmetro random_page_cost de acordo: enquanto o valor padrão de 4.0 foi calibrado na era dos HDDs (onde um acesso aleatório custava 4 vezes mais que um sequencial), em NVMe esse valor deve ser reduzido para 1.0–1.5, refletindo o fato de que o seek praticamente inexiste. Essa simples alteração de configuração frequentemente faz o planejador do PostgreSQL preferir index scans a seq scans, resultando em ganhos imediatos de PostgreSQL performance sem qualquer mudança estrutural.
Outro aspecto frequentemente negligenciado é o impacto do storage na paralelização de queries. O PostgreSQL pode disparar múltiplos workers para varrer partições ou executar hash joins em paralelo, mas se o storage não consegue alimentar esses workers com dados na velocidade necessária, o paralelismo se torna contraproducente — os workers passam mais tempo esperando I/O do que processando. NVMe SSDs, com suas filas de comando profundas e baixíssima latência, permitem que o paralelismo realmente entregue aceleração linear, um fator crítico para PostgreSQL performance em cargas analíticas. Se você ainda opera sobre SATA SSD ou — pior — HDD, entre em contato conosco para um assessment de migração; o ROI dessa troca de infraestrutura costuma se pagar em semanas, não meses.
Vacuum e Autovacuum: Impacto Direto na PostgreSQL Performance
O vacuum é, sem exagero, o subsistema mais incompreendido do PostgreSQL e, paradoxalmente, um dos que mais impactam PostgreSQL performance de forma silenciosa e progressiva. O PostgreSQL 18 trouxe avanços documentados pela AWS que elevam o autovacuum a um novo patamar de eficiência, mas os fundamentos continuam sendo essenciais para qualquer DBA que deseje manter a performance ao longo do tempo. Na JRT Technology Solutions, estimamos que 40% dos incidentes de degradação gradual que investigamos têm raiz em configurações inadequadas de vacuum — tabelas com dead tuples acumuladas, índices inchados e wraparound de transaction ID se aproximando perigosamente.
O mecanismo é engenhoso, mas tem custos operacionais. O PostgreSQL utiliza MVCC (Multiversion Concurrency Control), o que significa que updates e deletes não sobrescrevem ou removem fisicamente as tuplas antigas — elas são marcadas como “mortas” e permanecem ocupando espaço nas páginas do
Gostou do conteúdo? Fale com nossos especialistas!
A JRT Technology Solutions está pronta para implementar, configurar e dar suporte às tecnologias abordadas neste artigo.